
-

Naveen Mp
- 2025/11/07
Traditional vs. Serverless ML Service Deployment in AWS: A Real-World Comparison
Artificial Intelligence and Machine Learning are revolutionizing industries, from large language models to computer vision and beyond. But getting ML right isn't just about building a great model; deployment strategy plays a critical role in its success and cost-efficiency.
Here, we share our experience migrating a crucial ML service for a customer providing GPS-based services to US law enforcement agencies, comparing a traditional EC2-based approach with a modern AWS serverless architecture.
The Use Case: Automatic License Plate Recognition (ALPR)
Our customer needed an Automatic License Plate Recognition (ALPR) application. This app scans suspicious vehicle number plates from a live stream (via an RTSP endpoint), fetches metadata via an external API, and instantly generates alerts for stolen vehicles.
The Core Solution
The backend service connects to the mobile app via a socket server and processes the live stream:
- Frame Extraction: Uses YoloV5 to extract number plate frames as images.
- OCR: Feeds images into an OCR library to identify the number plate as plain text.
- Metadata Fetch: Uses the plate text to call a third-party API for vehicle-specific information.
- Instant Feedback: Sends inference data and metadata back to the app in real-time.
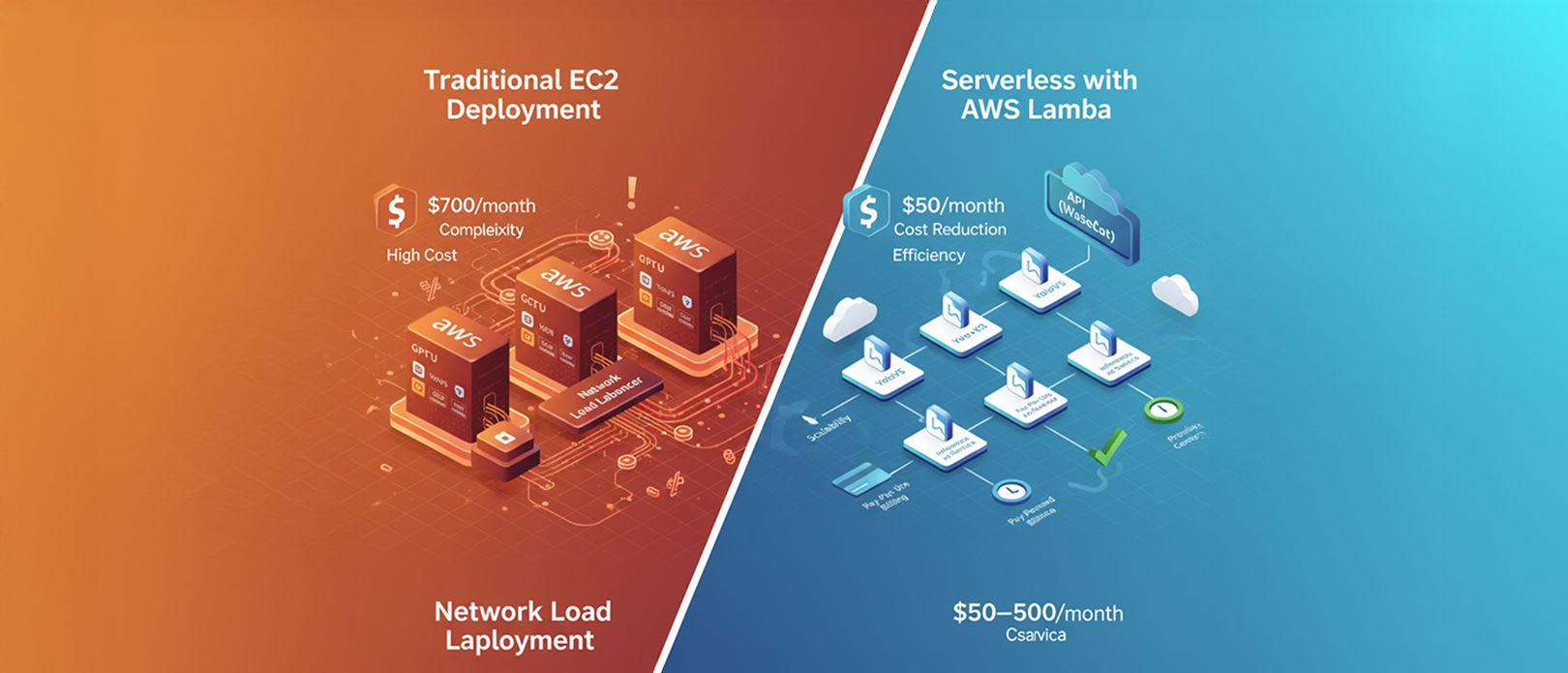
The Existing: Traditional EC2 Deployment
The initial architecture was a traditional, instance-based approach running on AWS:
- Infrastructure: Socket server, inference service (YoloV5, OCR), all running in GPU-equipped EC2 instances.
- Scaling: Managed by a Network Load Balancer (NLB) and an Auto Scaling Group (ASG).
- Optimization: Models were preloaded on server startup since loading is time-consuming. Each user's inference was handled in a single thread per instance.
Pain Points with the Traditional Setup
While functional, this architecture quickly showed its limits as the service grew:
- High Infrastructure Cost: The recurring minimum monthly cost (EC2, NLB, Logging) was approximately $700, paid regardless of usage volume. This spending was becoming difficult to justify against the app's revenue.
- Operational Complexity: The inference service code was choked with complex threading logic to manage multiple simultaneous users, making it difficult to maintain.
- Performance: The complex threading was slowing down the response time despite preloading.
- Scaling Inefficiency: Inference was memory-intensive, causing new instances to spin up at a high rate.
The Improved: Serverless Deployment with AWS Lambda and Websockets
We decided to move entirely to a serverless architecture to resolve these pain points. The core idea was elegant: replace the complex inference thread of a user with a single AWS Lambda call.
New Serverless Architecture
- Inference as a Service: The prediction models and inference services are bundled into an image using the AWS base image for Lambda.
- Trigger: The Lambda is triggered via a WebSocket API in the AWS API Gateway.
- Process Flow: On every user stream, a Lambda is triggered, which handles the entire inference process for that single user—no shared instance, no complex threading.
Key Advantages of Serverless
| Feature | Traditional (EC2) | Serverless (Lambda) |
|---|---|---|
| Infrastructure | Provisioned EC2 Instances, NLB, ASG | Zero on-demand instances |
| Cost | Fixed minimum monthly cost (approx. $700) | Pay-per-execution (Cost was between $50 and $500 based on usage) |
| Code Complexity | High (complex threading logic) | Low (single-thread per execution) |
| Scaling | Limited by ASG/NLB configuration | Unlimited horizontal scaling by Lambda |
The cost savings alone were compelling: the infrastructure became elastic, costing as little as $50 per month during low-usage periods, which was a massive improvement over the fixed $700 baseline.
Dealing with Latency: Model Loading in Lambda
In a serverless model, the environment might have to be re-initialized for each request, and loading a large ML model can introduce significant latency (the dreaded "cold start").
We mitigated this using AWS Provisioned Concurrency. This feature keeps a configured number of Lambda function environments initialized and ready to take requests, essentially eliminating the cold start for frequently accessed functions. We judiciously planned the concurrency settings to balance latency needs with cost, as provisioned concurrency is chargeable.
Trade-Offs and Conclusion
While the migration was highly successful, we acknowledged two key trade-offs:
- Lambda Time Constraint: AWS Lambda has an execution time limit of 15 minutes. Our customer was fine with this, as their typical streaming use case never exceeded that duration.
- Per-Plate Delay: The YoloV5 and OCR prediction had an inherent 3 to 5-second delay for each number plate. This was acceptable for security officers, who are typically walking or slow-driving while scanning.
Migrating an entire production system is challenging, but the beauty of serverless is that it can be achieved piece by piece. By moving the core inference service to AWS Lambda and a WebSocket API, we dramatically reduced infrastructure costs, simplified the codebase, and gained massive scalability without the operational headache of managing instances and threading.
Ultimately, technology finds its true purpose when it delivers transformative value to the end customer. For us, that value was delivered through massive cost reduction and superior scalability enabled by the serverless approach. - Naveen Mp, Principal Engineer
Ultimately, technology finds its true purpose when it delivers transformative value to the end customer. For us, that value was delivered through massive cost reduction and superior scalability enabled by the serverless approach.

